


A l’heure du Big Data et de la transformation digitale, de nombreuses entreprises font le choix de réorganiser leur système d’information pour exploiter cette nouvelle manne de données. L’augmentation exponentielle du nombre d’objets connectés et des données qu’ils génèrent, pousse les entreprises privées et le secteur public à restructurer leur système d’information.
On remarque que les données géographiques y tiennent une part de plus en plus importante. La cartographie interactive et collaborative (OpenstreetMap) ainsi que l’Open Data y contribuent. Leur exploitation, peut prendre différents aspects : géomarketing, analyse spatiale, calculs d’itinéraires, positionnement en temps réel, génération de documents réglementaires liés à l’urbanisme et l’environnement…
Mais avant de pouvoir exploiter ces données il est essentiel de mettre en place certaines bonnes pratiques pour bénéficier au maximum de la puissance d’analyse liée aux données géographiques.
Choix de la technologie
De nombreux systèmes de gestion de base de données (SGBD) proposent désormais une extension spatiale de leur socle traditionnel. Que ce soient des bases de données propriétaires ou Open Source. De nombreuses entreprises dont l’activité est centrée sur l’analyse et l’utilisation de données spatiales se tournent vers le SGBD PostgreSQL et son extension PostGIS qui est, à l’heure actuelle, une des plus complète et puissante du marché. En effet PostGIS dispose d’environ 1500 fonctions spatiales et implémente tous les standards définis par l’OGC (Open Géospatial Consortium)

Configuration de la base de données
Les bases de données spatiales contiennent généralement des entités plus volumineuses que les bases de données traditionnelles. Il est donc important de pouvoir adapter la configuration en fonction des besoins. La configuration par défaut du SGBD PostgreSQL est adaptée à une Base De Données traditionnelle.
En revanche si l’on souhaite une utilisation en production de données spatiales, il est indispensable de procéder à quelques modifications des paramétrages pour rendre les calculs efficaces et plus rapides.
Ces paramètres sont accessibles dans le fichier « postgresql.conf » situé dans le dossier « data » de PostgreSQL. Une fois que les paramètres sont modifiés il suffit de redémarrer le service PostgreSQL.
Il est également possible de visualiser l’ensemble de ces paramètres via la commande « show all ; » depuis l’interface en ligne de commande, ou l’interface graphique pgAdmin.
Mais également de les modifier en utilisant la syntaxe suivante :
SET paramètre TO 'valeur';
Ex : SET maintenance_work_mem TO '1GB';Optimiser les paramètres du serveur
shared_buffers
Cette option permet de choisir la quantité mémoire dédiée au serveur PostgreSQL pour la mise en cache. La valeur par défaut proposée (128Mo) est clairement insuffisante dans le cas d’une base de données spatiales à forte volumétrie. Il est recommandé d’augmenter la valeur à 500 Mo pour un système disposant de 32Go de RAM.
work_mem
Défini la mémoire maximale utilisée pour chaque requête complexe par PostgreSQL avant d’utiliser le disque. La valeur par défaut est de 4Mo ce qui est très insuffisant dans le cas de requêtes complexes. Il est conseillé de passer au moins à 64Mo voir 128Mo selon les capacités physiques de la machine.
Les optimisations liées à la configuration du serveur sont terminées.
Optimiser la base de données
Nous allons aborder les différentes optimisations liées aux données. En commençant par un focus sur l’outil d’analyse et de planification fourni par PostgreSQL.
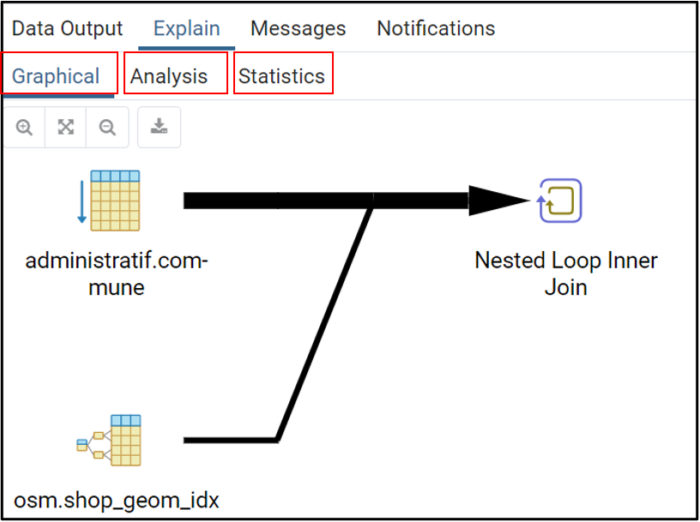
Explain Analyse
EXPLAIN : Conçoit un plan d’analyse pour les requêtes et présente le coût de chacune des instructions.
ANALYSE : Collecte les statistiques sur le contenu des tables qui seront ensuite utilisées par le planificateur.
PostgreSQL propose un outil de planification de requête qui permet à l’administrateur de visualiser le temps d’exécution des différentes étapes de l’instruction. Le résultat de cette requête est présenté sous forme d’arborescence où les différents nœuds correspondent aux actions réalisées lors du traitement par PostgreSQL. Les statistiques de chaque étape sont affichées en millisecondes. Cette commande est très utile car elle nous permet de décomposer la requête, voir quelles sont les actions les plus coûteuses en temps et ainsi nous permettre d’optimiser le script.
Validation de la qualité des données
Il est indispensable de s’assurer de la qualité des données géographiques lors de leur intégration dans la base de données. L’ensemble des requêtes spatiales effectuées sur ces données seront performantes uniquement si la géométrie des enregistrements est valide. Dans le cas contraire les traitements spatiaux risquent d’échouer, ou de prendre un temps considérable.
Il est donc nécessaire de s’assurer de la validité de l’ensemble des géométries des entités présentes en base. Mais également de créer des fonctions de validation et correction de géométries, exécutées dans des déclencheurs lors de l’insertion ou la modification d’un enregistrement. Cela permet de s’assurer que les données nouvellement insérées ou modifiées ont une topologie valide.
PostGIS, l’extension spatiale de PostgreSQL dispose de plusieurs fonctions d’analyse de validité des géométries. La fonction ST_IsValidReason() prend en paramètre la géométrie de l’enregistrement et renvoie un texte pour indiquer si la topologie est valide. Si la géométrie est invalide elle précise la raison. Cela permet donc d’analyser la raison et de la corriger en conséquence. L’automatisation des scripts de correction de géométrie est un levier d’amélioration continue des process de traitement de l’information spatiale.

Dans le cas ci-dessus la géométrie de la commune de Plan de Cuques est invalide à cause d’une auto-intersection aux niveau des coordonnées précisées dans le tableau.
SRID
L’identifiant de référence spatiale (Spatial Reference Identifier ou SRID) permet d’identifier de manière unique les systèmes de projection. Il en existe plus de 5000. Ils sont référencés dans la table spatial_ref_sys dans la base de données PostgreSQL lorsque l’extension postGIS y est installée. Pour que les coordonnées des objets géographiques aient de l’intérêt, le système de projection doit impérativement être défini. En effet le positionnement d’un objet dans l’espace dépend à la fois de ses coordonnées cartésiennes (X, Y) ou GPS (latitude, Longitude) mais également du système de projection utilisé.
Lors de requêtes spatiales sur différentes tables il est indispensable que les systèmes de projection soient identiques pour que les traitements fonctionnent. Dans le cas contraire le résultat des requêtes sera nul ou tronqué. Il est possible de transformer la projection de la table dans la requête de jointure mais cela implique évidemment un coût supplémentaire de la requête.
Pour faire une jointure spatiale entre deux tables qui n’ont pas la même projection on doit obligatoirement transformer la projection de l’une des deux table dans cette requête de jointure. Cela signifie que pour toute les lignes d’une table, la géométrie sera projetée dans un autre système de projection.
Par exemple si l’on souhaite joindre spatialement deux tables qui n’ont pas la même projection, on doit transformer la projection « à la volée » en utilisant la fonction postGIS ST_Transform(). Cette fonction prend en paramètre la géométrie de l’entité et le système de coordonnée cible. Il va y avoir une boucle sur tous les enregistrements pour reprojeter la géométrie de toutes les lignes de la table concernée.
Dans un soucis de performance et d’homogénéisation des données il est donc conseillé que l’ensemble des tables géographiques d’une base de données utilisent le même système de projection. Si toutefois il n’est pas possible d’utiliser un seul SRID, il est préférable d’appliquer la fonction de transformation sur la table contenant le moins de lignes.
Indexation spatiale
L’indexation spatiale est un élément clé lors du requêtage de données géographiques. Comme pour les bases de données traditionnelles, la création d’un index permet d’accéder de manière efficiente à une entité géographique sans passer par une analyse séquentielle de chaque enregistrement des tables concernées. Cette technique est indispensable lors de traitements spatiaux tels que la jointure spatiale. Selon la volumétrie des tables concernées par la jointure spatiale, l’indexation permettra de diviser le temps de traitement par 5 ou 10, ce qui représente une optimisation conséquente.
Clustering
Action permettant d’accélérer l’accès aux données liées géographiquement. La création de Cluster sur les index spatiaux peut également avoir un impact important sur le temps de traitement des requêtes spatiales. Mais contrairement aux précédentes manipulations, le gain sera conséquent uniquement sur les très grands ensembles de données. Si les tables à requêter contiennent chacune moins de 20 000 lignes, le gain ne sera pas flagrant. Cependant dans le cas de tables très volumineuses, le temps de traitement peut être réduit de 15 à 20%.
Mise en pratique
Pour illustrer les différentes optimisations vues précédemment, prenons l’exemple d’une requête de jointure spatiale. D’une part, nous avons une table avec les communes du territoire de France métropolitaine et de l’autre, une table des commerces de la région Sud. On souhaite à partir de ces deux tables ne récupérer que les enregistrements correspondant aux commerces du département des Bouches-du-Rhône.
La première table compte environ 35 000 enregistrements de type polygones et la seconde près de 18 000 de type Point.
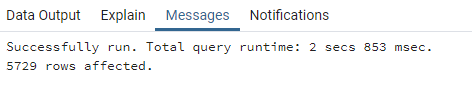
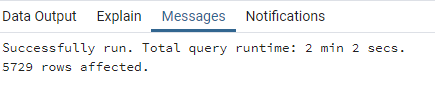
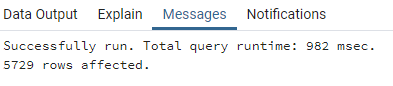
Voici le temps de traitement de la même requête de jointure en fonction des différentes optimisations présentées précédemment.
Sans index spatial & Systèmes de projection différent :
Reprojection à la volée de la table shop (17 812 Points)
Reprojection à la volée de la table communes (34 968 Polygones)
Avec index spatial :
Avec même système de projection :
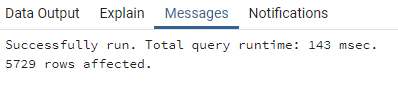
Avec cluster sur l’index spatial :
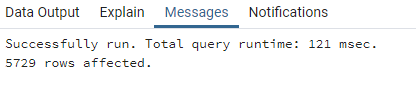
Les gains dans le temps de traitement varient en fonction de la requête. Dans les exemples ci-dessus, les différentes techniques d’optimisation permettent de réduire considérablement le temps de traitement.
Il existe de nombreuses techniques d’optimisations, tant sur la configuration et l’administration de la base de données que sur le requêtage. Celles-ci seront spécifiques à la volumétrie de vos données ainsi qu’a leur structure. Ces possibilités pourront êtres abordées dans un prochain article.








")
")










